幻觉 Hallucination
AI生成内容会出现幻觉(Hallucination)问题,主要因素一是LLM的概率生成机制,预测下一个词,可能会引致生成与事实不符的内容;二是训练数据有限,回答无法掌握更多私有的知识与最新的信息。
检索增强生成 RAG
RAG(Retrieval-Augmented Generation)则是为了更好的解决幻觉问题,提升模型的输出质量。有以下优势:
- 减少幻觉
- 提供当前时间的信息与特定领域的信息
- 与模型微调(fine-tuning)每次预训练静态数据相比,更有效率与性价比
RAG 流程图
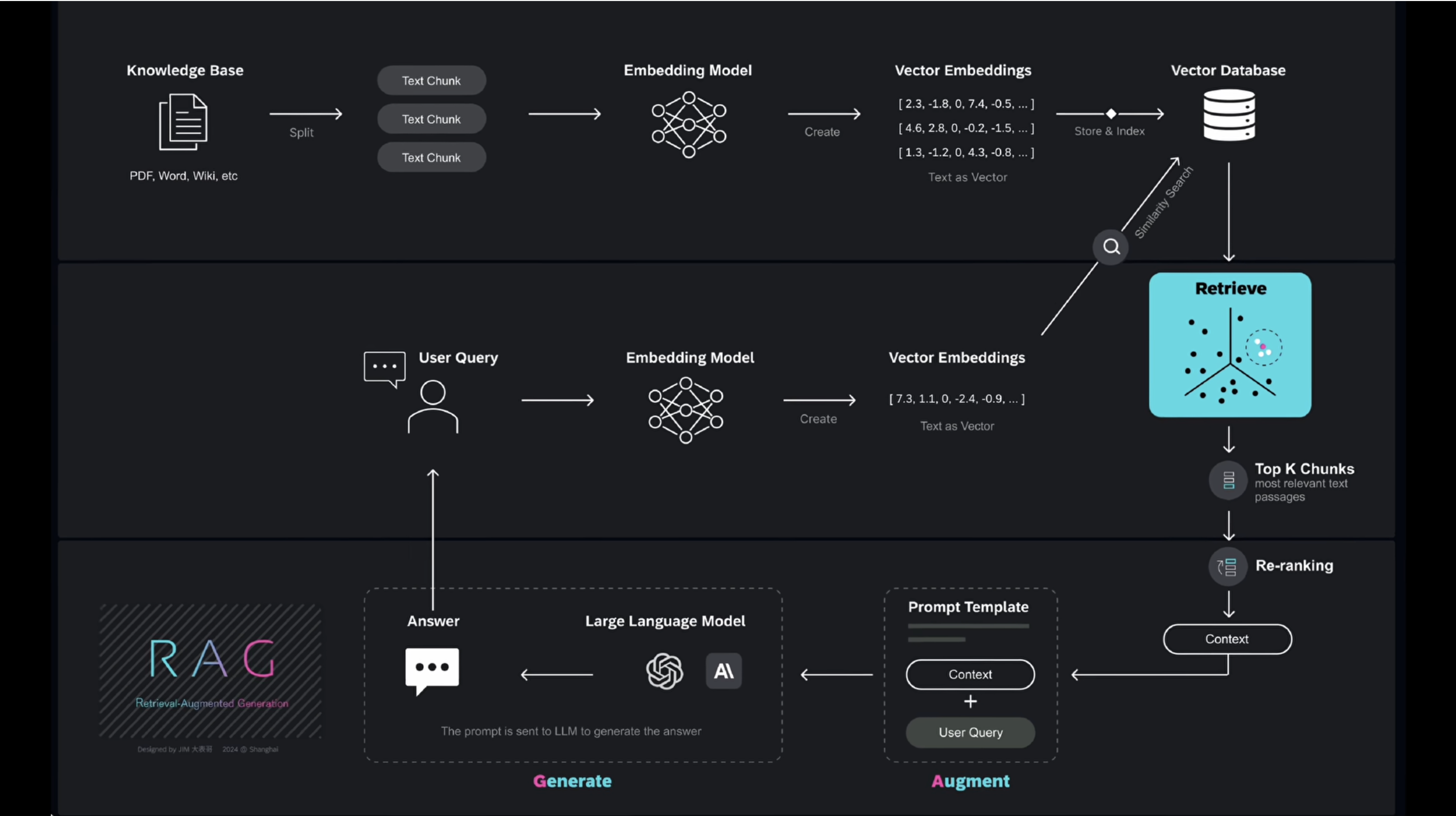
文本分块 Text Split
将知识库的各种文件、数据分割成 Text Chunk,分割的好坏影响RAG的效果
嵌入模型 Embedding Model
一种机器学习模型,可以将高维输入数据(如文本、图像)转换为低维向量,这些低维向量捕捉了文本的语义信息,有多种模型可以生成向量嵌入,如OpenAI的text-embedding-3-large
向量嵌入 Vector Embedding
是将数据以数值向量的形式来进行表示,可以让ML算法能更轻松地对数据进行处理和解读,以数值形式捕捉对象间的语义关系,这些数值可以表示对象的特征。可以通过向量搜索或相似性搜索(Similarity Search)在向量空间中查找相似对象
向量数据库 Vector Database
存储Vector Embedding等海量的高维向量,主要用于处理与相似性搜索有关的任务。主流厂商有Pinecone/ milvus/ Chroma/ Redis等
向量数据主要是由非结构化数据(Un-Structured Data)(如文本、视频、音频等,占全球数据80%)通过嵌入模型(Embedding Model)转换为向量嵌入,结构化数据(Structured Data)则以表格形式存在,如传统的数据库,存储明确的数据类型
检索 Retrieve
本质上是在向量空间中寻找与查询向量最相似(相邻)的邻居
最常用的度量指标:
-
欧氏距离(Euclidean Distance)两点之间的直线距离
-
余弦相似度(Cosine Similarity)非零向量的夹角的余弦值,常用于基于文本的数据
-
点积相似度(Dot Product Similarity) 两个向量的模长以及夹角余弦值的乘积
找出Top K chunks ,然后在此基础上重新排序 Re-ranking,更准确地挑选最合适的片段
提示词模版
将提示词模版与检索得到的context以及用户问题组合构建,输入给LLM,得到最终的输出结果返回给用户
这些context通过向量搜索从知识库中检索出来的,然后经过解码/转化后形成自然语言文本
如何找到最近邻
暴力搜索 Brute force search
穷举所有数据点
近似最近邻算法 ANN (Approximate Nearest Neighbor search)
核心思想,通过权衡精度与效率,牺牲少量精度,来显著提升搜索速度。构建专门的索引结构(Index),优化搜索路径,有效缩减搜索空间,实现快速检索
向量索引(Vector Indexing) 预先计算Vector Embedding之间的相似度,并将相似的向量组织在一起的过程
多种技术路线:
Data Structure
-
Hash-based index : LSH
-
Tree-based index : ANNOY
-
Cluster-based index : HNSW
-
Graph-based index : IVF
Compression
- Vector Quantization: 标量量化 SQ / 乘积量化 PQ
当前最流行的算法:层次化可导航小世界 HNSW (Hierarchical Navigable Small World)
基于图结构的算法,高层级的图由较少的节点组成,可实现快速大范围跳跃,缩小搜索空间,最底层包括所有数据点,搜索过程从顶层开始,直到在最底层找到最近邻点
选择ANN算法时,通常会面临不可能三角:速度、准确性、内存,要做权衡(trade-off)